What works to prevent food fraud
Appendix 4: What works to prevent food fraud - full methodology
Methodology used in creating the report on what works to prevent food fraud.
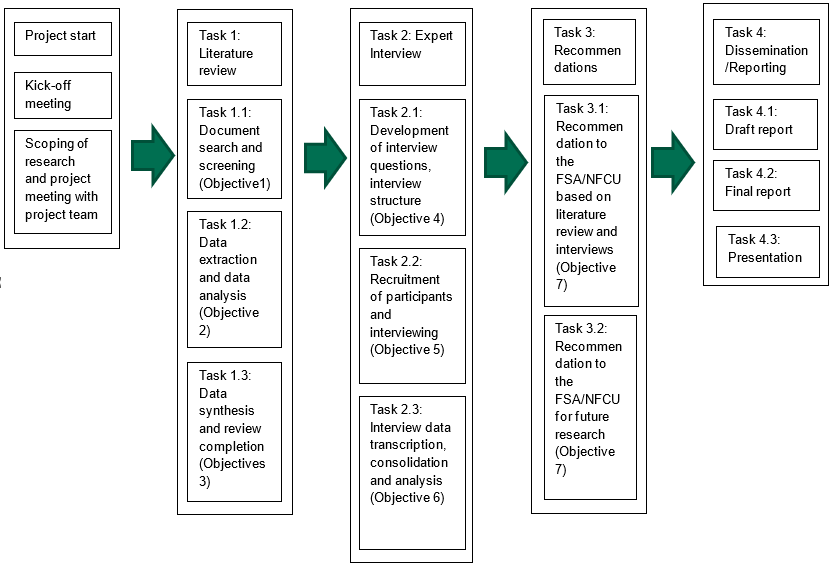
Our study workflow was split into four tasks (Figure 4.1):
- Task 1. Carrying out a literature review on domestic and international evidence
- Task 2. Conducting supplementary expert interviews to understand ‘what works’ or ‘what may work’ in preventing food fraud
- Task 3. Providing recommendations which could be adopted by the NFCU and incorporated into the Unit’s key strategies and for any future research required within this area
- Task 4. Reporting and dissemination of the final report
Figure 4.1: Diagram of study workflow and tasks
Literature review
The literature review had a comprehensive search strategy (as shown in Figure 3.2) considering all available evidence in the public domain, including peer-reviewed articles, grey literature (for example, government and industry reports), relevant government reports, European and International literature. This included previously published systematic and critical reviews, and relevant assessments, as well as primary research.
The main review questions were:
- What food fraud prevention strategies and initiatives have been implemented in the UK and other countries?
- What strategies/initiatives have been implemented to prevent and tackle commodity based fraud in other industries?
- What conditions need to be in place to enable fraud prevention strategies to be successful?
The key elements of the question (PIO): Population (P), Intervention (I), and Outcome (O), were:
- The population of interest included food and non-food physical products sector.
- All fraud interventions or prevention strategies used in food and non-food physical products sector.
- Relevant outcome measures for interventions or prevention strategies were what impact did the intervention or prevention have on fraud.
All fraud prevention strategies and initiatives were considered across sectors.
The primary source databases searched were Web of Science, Scopus, and EBSCOhost. The searches were restricted to records published from 1970 to December 2022. Finalised keywords agreed with the Agency and were:
Arts OR Banking OR Commodity OR Document OR Feed OR Financial OR Food OR “Food Crime” OR “Food Fraud” OR “Food Standards” OR Goods OR “Health care” OR Industries OR Ingredients OR Institutions OR International OR Manufacturing OR Medical OR Medicine OR Pharmaceutical OR Services OR “Supply chain” OR Waste
AND
“Anti-fraud” OR Block OR “Campaign against” OR “Capable Guardians” OR Challenge OR CLEO OR CLUE OR Combatting OR Control OR “Food Crime Hotline” OR “Food Fraud Vulnerability Assessment” OR “Horizon Scanning” OR Intelligence OR “Intelligence Network” OR Interception OR Intervention OR MEMEX OR Policing OR Prevent OR Preventing OR Prevention OR QUACCP OR “Quality Assurance” OR “Routine Activity Theory” OR “Six Sigma” OR “Statistical Process Control in Food Industries” OR Stop OR TACCP OR Tackle OR VACCP
AND
Adulteration OR Authentic OR Authenticity OR Counterfeiting OR Crime OR Diversion OR “Economically motivated adulteration” OR Fake OR Fraud OR Illegal OR Integrity OR Misrepresentation OR “Natural Quality” OR “Substance Quality” OR Risk OR Substitution OR “Supply chain vulnerability” OR Tampering OR Theft OR Traceability
Focused Google searches were used to identify relevant grey literature.
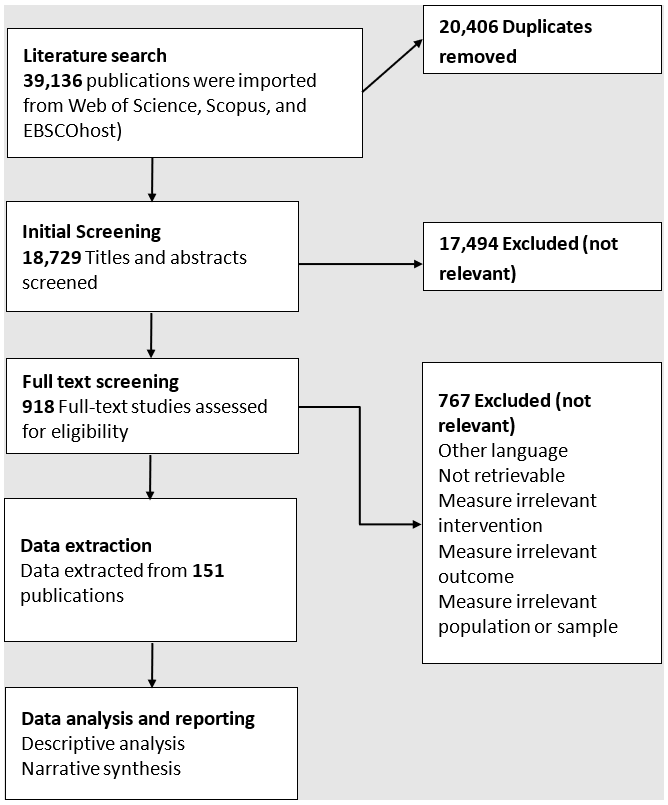
In total 39,132 citations were initially identified in Web of Science, Scopus, and EBSCOhost. There was considerable overlap between the databases with 20,406 duplicates. Additional records were identified through Google searches, other references, and through contact with authors. For all searches, citations and abstracts were uploaded from each of the electronic databases into Covidence (an online tool for systematic reviewing). The following exclusion criteria were applied:
- They contain no relevant data on strategies for fraud or crime prevention.
- Were in a language other than English.
The criteria were independently applied to the abstract of each paper by at least two members of the seven-member project team. For each citation, a consensus was reached that the citation is relevant for inclusion. Arbitration by a third member of the project team was used to settle conflicting appraisals. 18,726 abstracts were screened, and 17,494 references excluded. Full texts were obtained for all abstracts that passed the inclusion criteria.
A total of 915 publications were considered relevant by title and abstract and full texts collected for second screening. This number was reduced to 151 publications from which some data were extracted, with 703 references being excluded because they were not relevant. An in-depth content analysis of the selected articles was carried out. With the key elements of interest from each paper extracted. To synthesise the data extracted and evaluate its quality a narrative approach was used. This was used to; a) develop a synthesis of findings of each article, b) investigate relationships within and between articles, and c), evaluate the degree of robustness of the synthesis.
Interviews
In parallel to the literature review, a series of semi-structured interviews with professionals working on food fraud/crime were carried out. The purpose of the interviews was to get an in-depth understanding of what is currently going on around food fraud prevention and what can be done to improve prevention practices across the sector. The differences between detection and prevention where also discussed at some length.
Development of interview questions, interview structure
An interview protocol was created based on various topics that emerged from the evidence review that was conducted prior to the interviews (Appendix 4). The overall research aims, and research questions highlighted in the review section were put into consideration when developing the interview protocol and questions.
Before the online video interviews commenced the interview questions and interview protocol document was submitted to the University of Lincoln ethics department for ethics approval and to the FSA for review and approval.
Recruitment of participants and interviewing
We utilised a non-probability purposive sampling technique for the selection and recruitment of participants for the interview component of this study. This is a well-known sampling technique for the identification and selection of participants and proven to be the most effective when there are limited resources (Patton, 2002). Based on the expertise and experience of the members of the project team, decisions were made on which organisations/individuals to be interviewed. In the selection of international and domestic participants we ensured as best as possible to include representatives from Official Controls, the regulators (Environmental Health/Food Crime Units where relevant), industry representative bodies, industry network (such as the Food Industry Intelligence Network (FIIN)), policymakers and experts (such as academic, researchers, consultants).
Some participants worked in senior roles for multi-national companies involved in the food industry and others worked for SME food companies. We also interviewed accountants involved in auditing the food sector, individuals working in laboratories testing food, and individuals working for Local Authorities, NGOs, and organisations such as the WHO and UN.
A total of 16 in-depth semi-structured virtual interviews were conducted as part of this study. Each interview lasted for around 90 minutes. For the interviews, qualitative research methods allowed collection of in-depth information directly from the interviewees covering agreed question areas/topics while also giving the interviewees the opportunity to expand on their responses as they felt appropriate.
Prior to the interview a pilot interview was conducted (Steinar, 2007) which assisted in the refinement of the final interview questions/topics. Identified potential participants were contacted and interview dates and times were agreed. Interviews were conducted with two research team members being present. Participants’ consent for the interview and the recording of the interview was confirmed and agreed before the interview.
Interview data transcription, consolidation, content and thematic analysis
All interviews were recorded and then transcribed in Microsoft Teams. The interview transcription was checked after each interview by one of the research team for completeness and accuracy. Once the transcription has been reviewed it was anonymised and emailed to the participant for confirmation Content analysis of the transcribed interview was used to identify specific vocabulary and language through open coding using NVivo (Miles and Huberman, 1994) and the patterns and themes that emerged from the text were drawn out (Schreier, 2012). Axial coding brought the open codes together following the work of Braun and Clarke (2021) namely 1) data familiarisation; 2) systematic data coding; 3) generating initial themes; 4) developing and reviewing themes; 5) refining, defining and naming themes; and 6) writing the report.
Revision log
Published: 10 October 2023
Last updated: 11 April 2024